DB
Sharding
창욱씨
2020. 5. 8. 22:54
반응형
1. Sharding이란
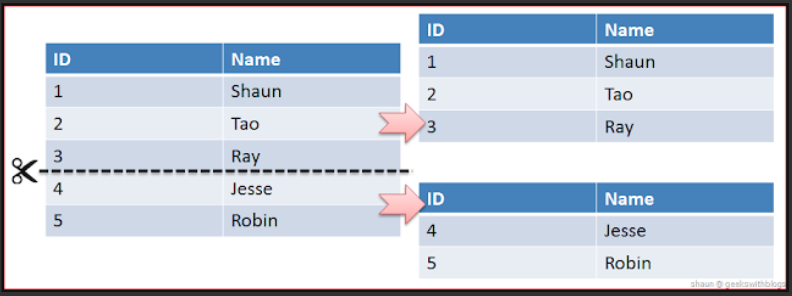
Sharding이란 단일의 데이터를 다수의 데이터베이스로 분산시키는 것을 말합니다. 이렇게 데이터를 분산시킴으로써 인덱스의 크기를 줄이고 작업 동시성을 늘릴 수 있습니다. Sharding은 Application Level에서도 가능하지만 Database Level에서도 가능합니다. 데이터베이스를 Sharding하게 되면 기존에 하나로 구성될 스키마를 다수의 복제본으로 구성하고 각각의 Shard에 어떤 데이터가 저장될지를 Shard Key를 기준으로 분리합니다.
2. Sharding 방법
Algorithm Sharding

데이터베이스 ID를 단순하게 나누어 샤딩하는 방식입니다. Sharding Key는 hash(key) % NUM_DB 같은 방식입니다.
장점
- 같은 값을 가지는 key-value 데이터베이스에 적합합니다.
단점
- Cluster를 포함하는 Node의 개수가 변하게 되면 Resharding이 필요합니다.
- Hash Key로 분산되기 때문에 공간에 대한 효율이 부족합니다.
Dynamic Sharding

Dynamic Sharding은 Locator Service를 통해 Shard Key를 얻는 방법입니다. Algorithm Sharding과 다르게 Node의 개수가 늘어나더라도 기존 데이터의 Shard Key를 변경할 필요가 없기 때문에 확장에 유연한 구조입니다.
단점
- Data Relocation시에는 Locator Service의 Shard key Table도 일치시켜야 합니다.
- Locator Service에 의존이 강합니다. 그래서 Locator Service가 성능을 위해 Cache하거나 Replication하기 쉽지 않습니다.
Entity Group

동일한 파티션의 관련 엔티티를 저장하여 단일 파티션 안에서 추가 기능을 제공하는 방식입니다.
장점
- 하나의 물리적인 Shard에 쿼리를 진행한다면 효율적입니다.
- 하나의 Shard에서 강한 응집도를 가질 수 있습니다.
- 데이터는 자연스럽게 사용자별로 분리되어 저장됩니다.
- 사용자가 늘어남에 따라 확장성이 좋습니다.
단점
- Cross-partition 쿼리는 일관성의 보장과 성능이 부족합니다.
반응형