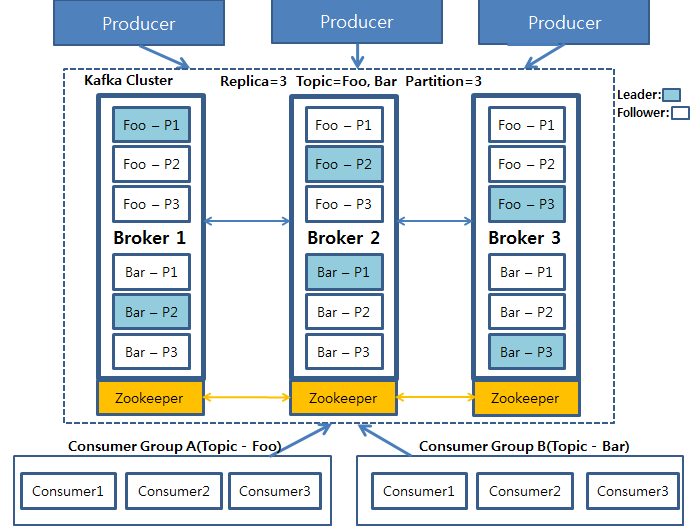
리벨런싱이란컨슈머 그룹 내의 컨슈머들은 자신들이 읽는 파티션의 소유권을 공유합니다. 즉 하나의 켠슈머 그룹에서 컨슈머 A가 담당하던 파티션 읽기 작업을 컨슈머 B가 이관받아 작업을 처리할 수 있습니다. 이와 같은 컨슈머 그룹 내의 소유권 이관 작업을 리밴런싱(Rebalance)라고 합니다. 이처럼 리밸런싱은 컨슈머 파티선 소유권을 조정할 수 있기 때문에 컨슈머 그룹의 확장성과 가용성을 높여줍니다.컨슈머 그룹 코디네이터컨슈머 그룹 코디네이터는 특정 컨슈머 그룹을 관리하는 브로커입니다. 즉, 컨슈머 그룹 별로 관리하는 브로커가 지정되는데 이 브로커가 해당 컨슈머 그룹의 코디네이터가 됩니다. 그룹 코디네이터는 아래와 같은 정보를 추적하고 관리하는데 만약 해당 정보에 대해 변경이 발생하면 리밸런싱을 실시합니다...